Great session on AI transformation from Matthew Green of Accenture at MnTech Connect today.

Great session on Shipping a Customer-Facing Al Agent: Lessons from Moving Fast Without Breaking Trust with Valentin Kornukh this morning. Shared learnings we have from creating SPS MAX!

Looking forward to a meaningful day of learning at today’s MnTech Connect event! Many good sessions on AI transformation including two led by TeamSPS! 🎉


“Your EFI shell is showing…”

This years family yearbook is another amazing time capsule. Tammy makes one each year and they are an instant family keepsake! So good.

Tyler and I went to Super Mario Galaxy and thought it was a lot of fun! 🍿

Testing out our new Bambu Labs P2S with a Benchy print!

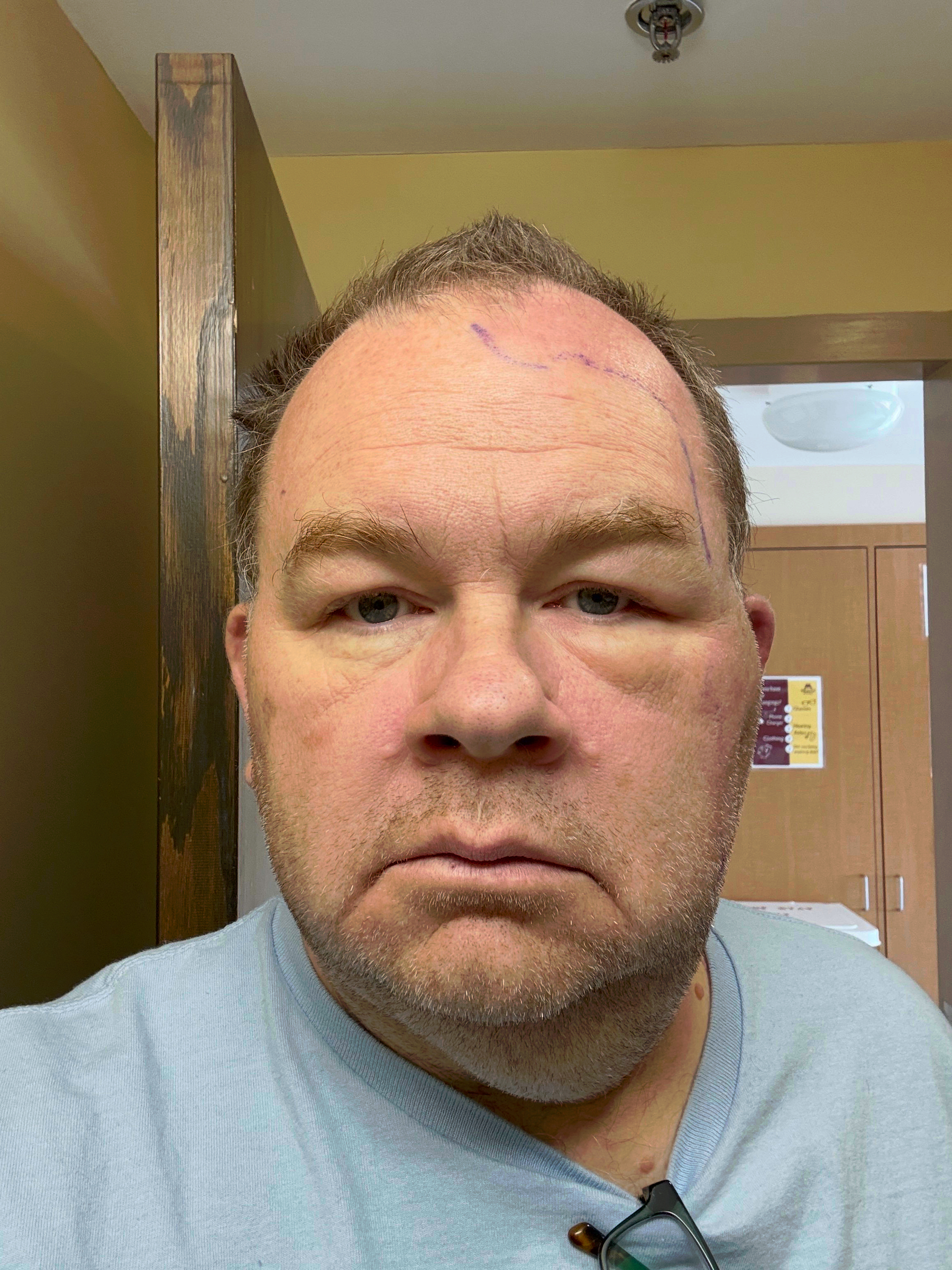
Facial Cellulitis
On Tuesday morning I went to work and felt fine. By about 11 am that day I felt really cold and was shivering. By 1 pm I had my head on my desk because I was so tired. I went home shortly after. My left ear started to hurt a lot and was inflamed. I thought I maybe had an ear infection? I slept all afternoon and that evening was hoping to still go see Bruce Springsteen in concert. I had a ticket but it wasn’t going to happen. A Dr. friend of mine suggested I go to the urgent care and that I looked like I had an infection. It was late and Tyler and I tried to go to a CVS MinuteClinic but they were closing. The next morning I went to a proper Urgent Care and they sent me to the Emergency Room.
The entire left side of my head was hot and hurt. There was an infection and it was going fast. By the time I got to the Emergency Room I could barely walk a block and they admitted me to the hospital with Facial Cellulitis and sepsis. Luckily it wasn’t MRSA but a rather straightforward, but super fast, Strep bacteria.
They put me on 24 hour fluids and antibiotics and I started to recover slowly. I ended up spending two nights in the hospital. The unflattering photo of me is actually right before checking out. You can see the line they had drawn on my face to mark the infection. I still felt rough but kept recovering.
Thank you for modern antibiotics. Without that, this would have been lights out for me.
I’ve tried to get used to “Click wallpaper to show desktop” for long enough now and I still despise it. Also “Show menu bar background” is a must. Annoys me that I now have to go set esoteric settings to make macOS work the way I want it to.
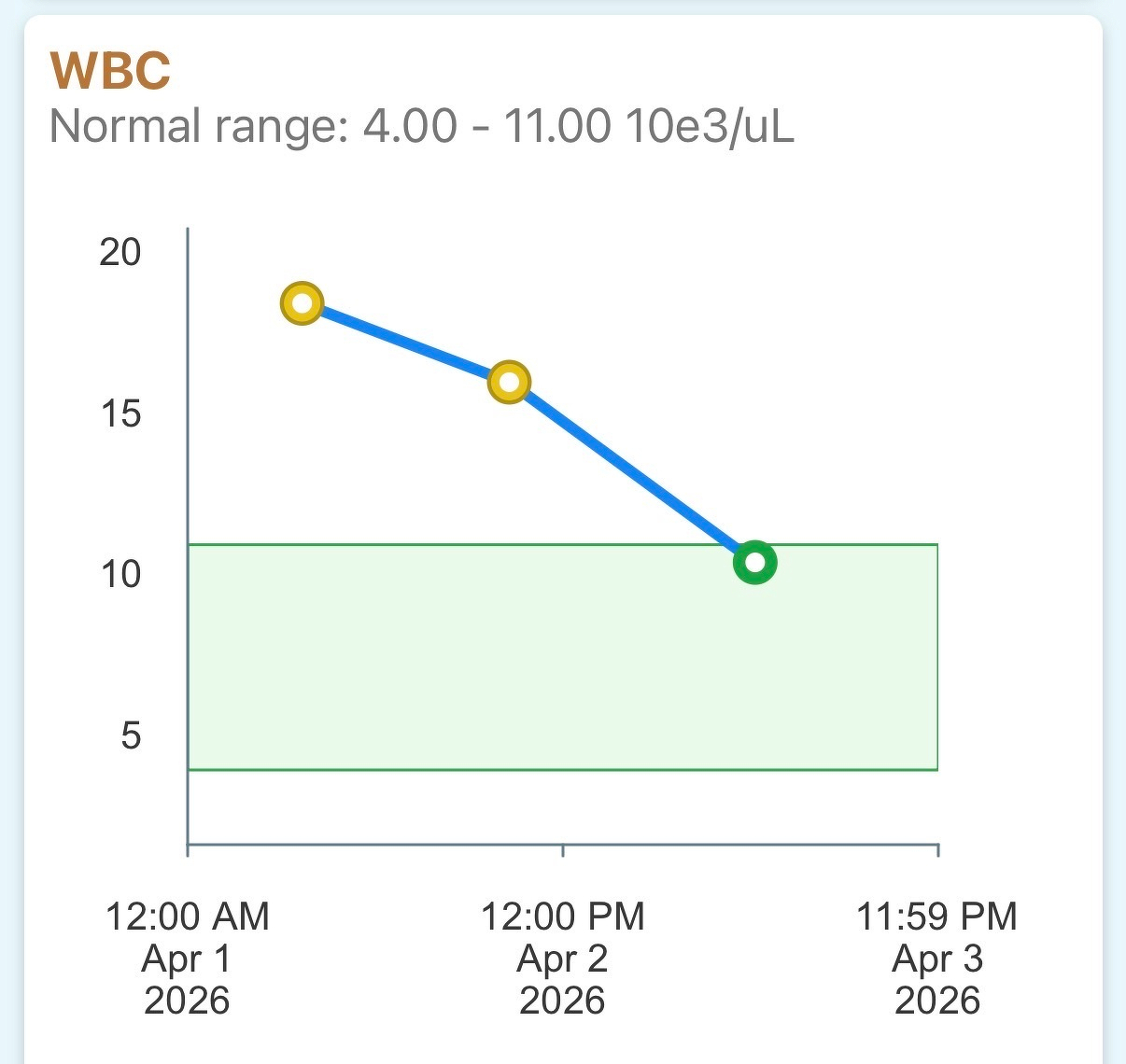
Happiest I’ve been from a graph for in a while.