
One Year for WikiApiary
Yesterday WikiApiary had a very meta tweet when it wished itself Happy Birthday! A while back I realized that if you looked the edit history of the “Main Page” of a MediaWiki website you could infer the date the wiki was started, it’s birthday. WikiApiary then wishes wikis a happy birthday on that date. Yesterday was WikiApiary’s big day.
Happy Birthday WikiApiary http://t.co/wRk4Cs5iO0 #MediaWiki #wiki
— WikiApiary (@WikiApiary) December 22, 2013

The first year of WikiApiary has been great! The comments people make about it and the great contributions that many people have made to the wiki reflect the utility and interest in the data. WikiApiary was a holiday break project for me in 2012 and it’s continued to get additions and modifications from a number of people throughout the world. It is the first project I’ve started that I feel has gotten a true community around it and people that are moving it forward independent of what I’m doing. That is really great! This idea of a “Wiki to track other wikis” clearly caught on with some people.
In WikiApiary’s first year it has collected 1,855,979,520 statistics samples in its database, just 2.6GB of data. As of today, WikiApiary is collecting data from 9,555 active wikis. It shows 2,478,637 active users over 384,870,041 pages with 2,894,060,197 edits in the part of the wikiverse that it monitors.
Looking at visitor activity during this first year, WikiApiary had 32,416 visits with 105,895 page views. 9,346 of those visits were from MediaWiki.org. The top 10 countries visiting the site were:
| Country | Visits | Pct |
|---|---|---|
| United States | 10,243 | 31.6% |
| Germany | 3,422 | 10.6% |
| United Kingdom | 2,095 | 6.5% |
| Russian Federation | 1,853 | 5.7% |
| France | 1,084 | 3.3% |
| Canada | 1,000 | 3.1% |
| Netherlands | 814 | 2.5% |
| India | 755 | 2.3% |
| Spain | 714 | 2.2% |
| China | 687 | 2.1% |
WikiApiary visitors weigh heavier than average to Linux.
| Operating System | Visits | Pct |
|---|---|---|
| Windows 7 | 14,989 | 46.2% |
| Linux | 4,029 | 12.4% |
| Windows XP | 3,876 | 12% |
| Mac OS | 3,473 | 10.7% |
| Windows 8 | 1,707 | 5.3% |
Chrome dominates the browser choice for WikiApiary visitors.
| Browser | Visits | Pct |
|---|---|---|
| Chrome 26.0 | 2,377 | 7.3% |
| Safari 6.0 | 2,319 | 7.2% |
| Chrome 30.0 | 2,087 | 6.4% |
| Chrome 28.0 | 1,976 | 6.1% |
| Chrome 27.0 | 1,756 | 5.4% |
2,455 of the 32,416 (7.6%) visits to WikiApiary were from logged in users. All websites statistics are from the amazing Piwik project. No data is shared with Google or other search engines.
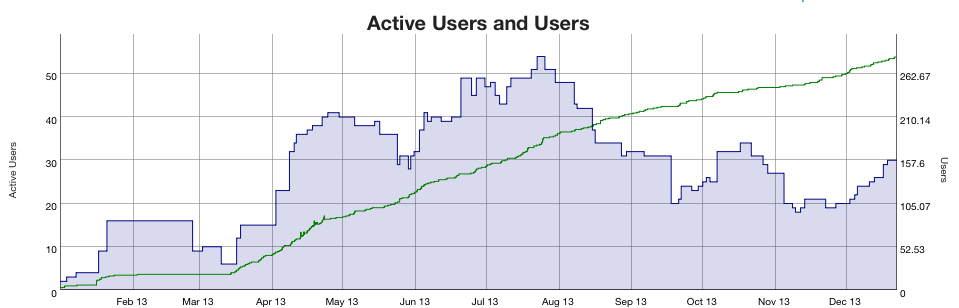
WikiApiary is largely about graphs, so that seems like a logical way to explore the first year of WikiApiary. The number of active users on WikiApiary has roughly been around 30 for most of the year, peaking over 50. This doesn’t seem like a ton, but most wikis that are monitored actually have fewer than 5 active users. The total number of users is over 250 and grows steadily. Those are all real accounts too, no spam accounts. Registration is required to edit so this is a good reflection of engagement.
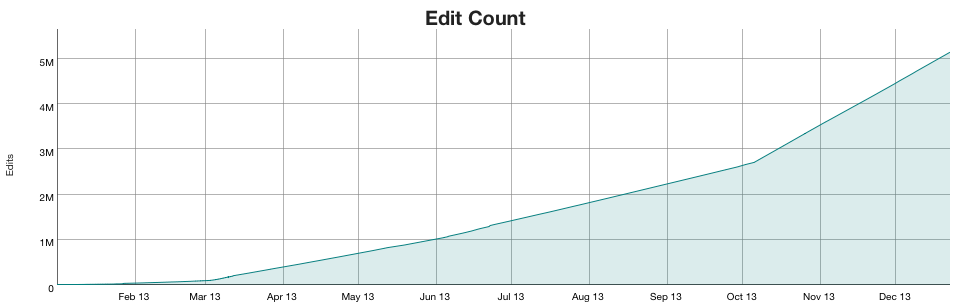
Edit activity on WikiApiary is mostly robotic. The bots are constantly tending to the data set and they do this with edits. You can see the edit rate jumped in October after I added tracking for MaxMind geo data as well as Whois records for wikis. Over 5 million edits in the first year.
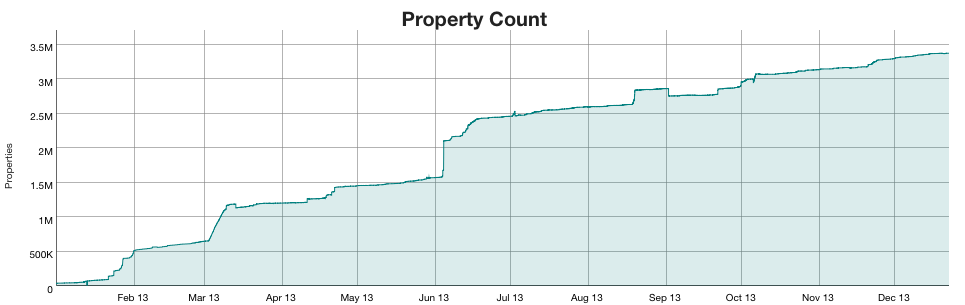
Total pages of content largely reflect the number of wikis being tracked, plus the number of extensions and skins that exist. Notably you can see the initial load of sites in February and March. There were additional farmer bots that added in some reasonably sized farms in June. In October the pages spike again with the addition of more datasets.

WikiApiary is itself the 11th largest Semantic MediaWiki installation that it tracks. The largest is Gyvosios gamtos enciklopedija with over 16 million properties (think of a property as a data value). WikiApiary has over 3.3 million property values.
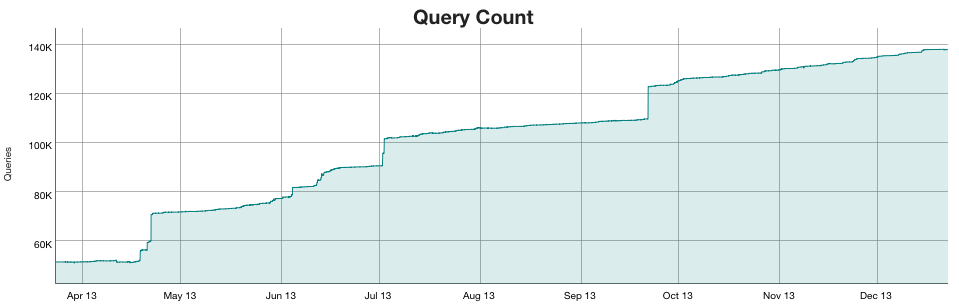
These 3.3 million properties are queried in MediaWiki templates so you can see the data. There are nearly 140,000 queries in WikiApiary.
Special Thanks
WikiApiary has had a lot of contributions with additions of wikis and help with templates and bots. Karsten Hoffmeyer has been a huge part of WikiApiary and is also an administrator on the site. Karsten helps with adding wikis and fending off the occasional bad edits. WikiApiary also has a very distinctive look from the Foreground skin which was built by my friend Garrick van Buren. Mark Hershberger has also been an active part of WikiApiary and is exploring ways that MediaWiki installs can automatically add themselves to WikiApiary. Huge thanks to Frederico Leva (Nemo) for linking extension pages on MediaWiki.org to their respective page on WikiApiary. This drives a lot of exposure for WikiApiary and provides great value to visitors of MediaWiki.org. A big thank you also to Paul DeCoursey who rewrote the Javascript code to embed the charts into the pages, and support multiple charts with usable controls.
Also, I think one of the things that makes WikiApiary unique is that it is built with MediaWiki and Semantic MediaWiki and the related suite of extensions. This is such a wonderful set of software and a special thanks to James HK, Jeroen De Dauw and Yaron Koren. All of them have helped out and provided input on WikiApiary at times in the first year.
Future Plans
I’ve got a ton of plans for WikiApiary, and I keep picking them off slowly. I’ve not had much time for the project the last couple of months but whatever time I have had has been going into rewriting the bots. The first versions were just hacked up and difficult to understand. I’m working on a rewrite that includes unit tests, a good object model and code that is easy enough to understand that I hope to get some more contributors involved. The other huge thing being added is parallel requests. Right now WikiApiary is limited in collecting from more sites due to how it collects, in serial. The new bots will do that in parallel and will dramatically change the cost of running a collection sequence. There should be no problem going from 10,000 to 100,000 or more wikis being monitored.
I would also like to see the Honey Bee MediaWiki extension get going which will be the first step of an extension that leverages WikiApiary inside of the wiki it’s running in.
Additionally I’d like to do a whole deeper level of analysis of MediaWiki websites and have been contacted by two groups who have written algorithms that do this and are interested in adding their code to WikiApiary. I hope to make that easier with the bot rewrite mentioned above.
I also want to provide a base Farmer class that can easily be extended so that bots that farm new wikis into WikiApiary are easier. My big objective is to finally pull in Wikia.
I’m proud of WikiApiary and plan on continuing to host it (no small feat actually, given its scale) and work on it. I see WikiApiary as one of my “decade project” so I don’t have to move too fast. I just keep things rolling the right way.